基于pupperteer的爬虫1
puppeteer中文文档:http://puppeteerjs.com/
开始
利用puppeteer文档中所给示例进行改动:
1 | const puppeteer = require('puppeteer'); |
更换目标网址:https://search.bilibili.com/all?keyword=CSS&from_source=nav_suggest_new
在网址中分析元素,获取要爬取的元素的选择器: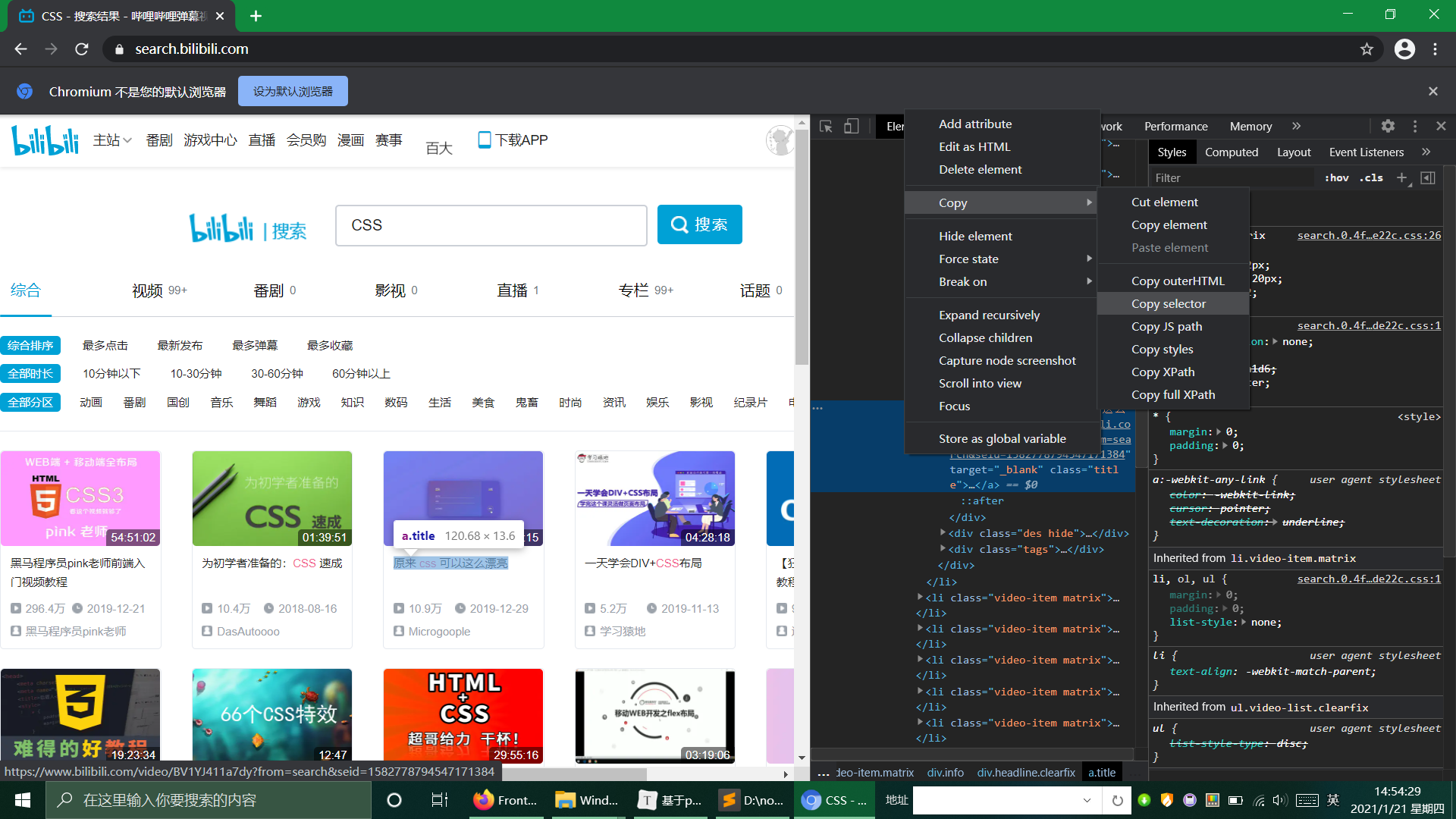

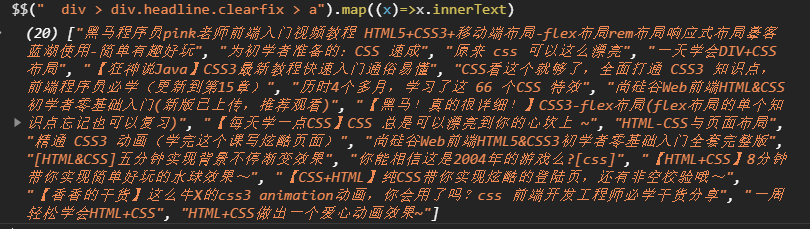
利用page元素的$$eval方法:
1 | let href = await page.$$eval("div > div.headline.clearfix > a", (links) => links.map((x) => x.href)); |
利用page的click方法点击下一页按钮:
1 | response = await Promise.all([ |
将爬取结果存入json文件
1 | fs.writeFile("data.json", JSON.stringify(all, null, "\t"), function (err) { |
或者Excel文件:
1 | fs.writeFile('a.xlsx', buffer, function(err) { |
全部源码:
1 | const xlsx = require('node-xlsx') |